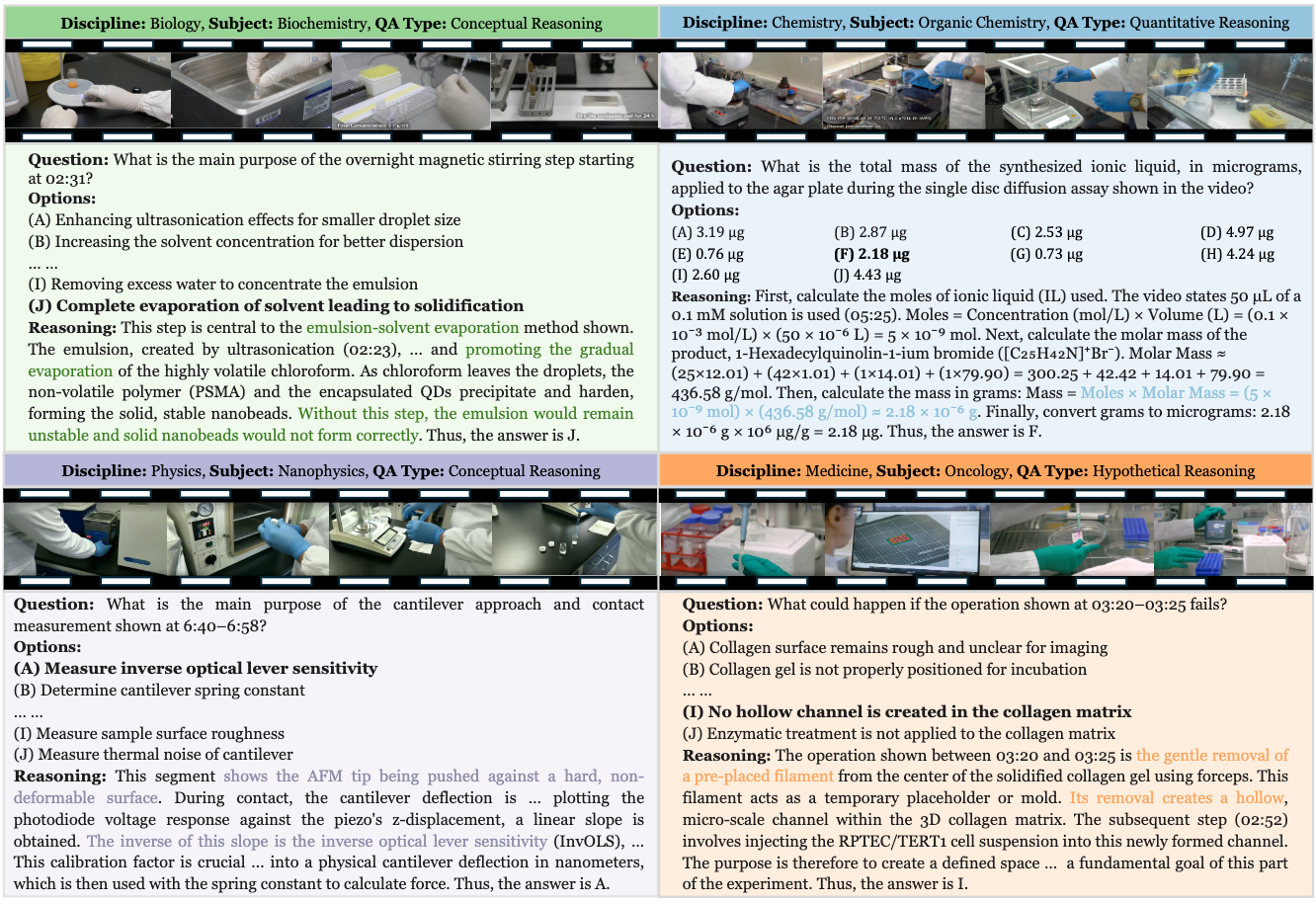
🎬 Dataset Examples










Benchmarking Scientific Video Reasoning in Large Multimodal Models
Large Multimodal Models (LMMs) have achieved remarkable progress across various capabilities; however, complex video reasoning in the scientific domain remains a significant and challenging frontier. Current video benchmarks predominantly target general scenarios where perception/recognition is heavily relied on, while with relatively simple reasoning tasks, leading to saturation and thus failing to effectively evaluate advanced multimodal cognitive skills.
To address this critical gap, we introduce SciVideoBench, a rigorous benchmark specifically designed to assess advanced video reasoning in scientific contexts. SciVideoBench consists of 1,000 carefully crafted multiple-choice questions derived from cutting-edge scientific experimental videos spanning over 25 specialized academic subjects and verified by a semi-automatic system. Each question demands sophisticated domain-specific knowledge, precise spatiotemporal perception, and intricate logical reasoning, effectively challenging models' higher-order cognitive abilities.
Our evaluation highlights significant performance deficits in state-of-the-art proprietary and open-source LMMs, including Gemini 2.5 Pro and Qwen2.5-VL, indicating substantial room for advancement in video reasoning capabilities. Detailed analyses of critical factors such as reasoning complexity and visual grounding provide valuable insights and clear direction for future developments in LMMs, driving the evolution of truly capable multimodal AI co-scientists.
We hope SciVideoBench could fit the interests of the community and help to push the boundary of cutting-edge AI for border science.
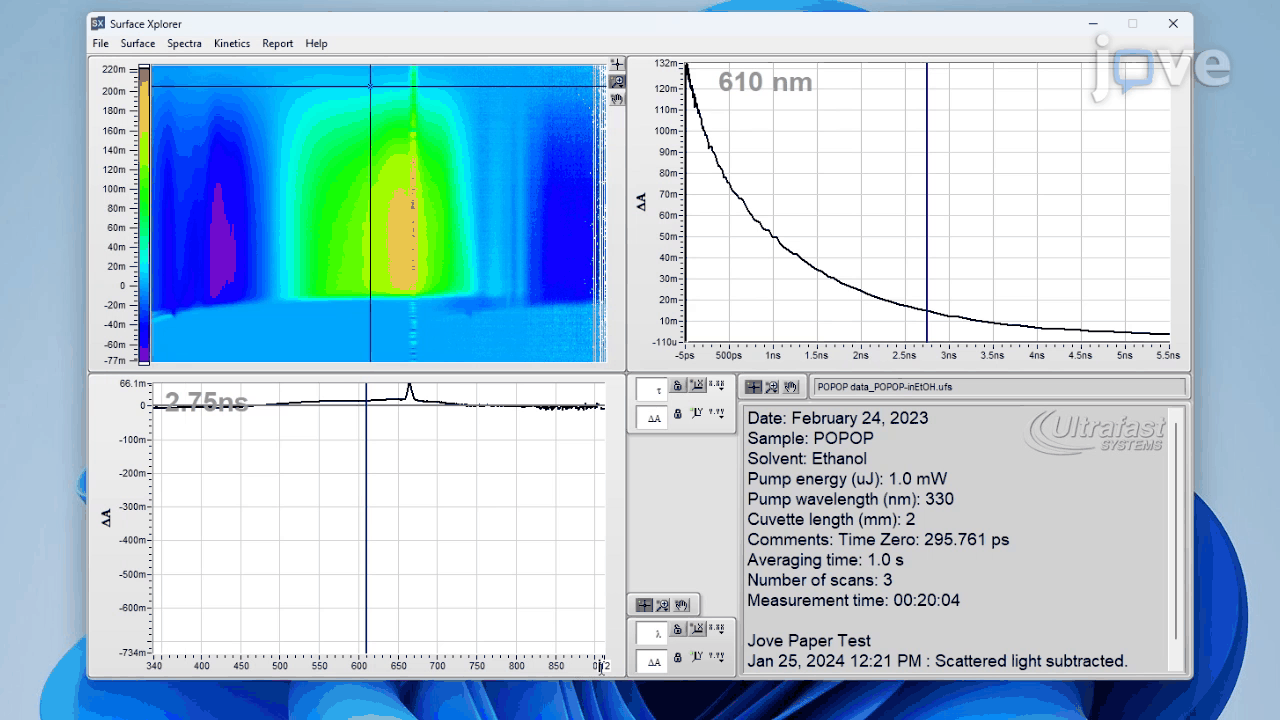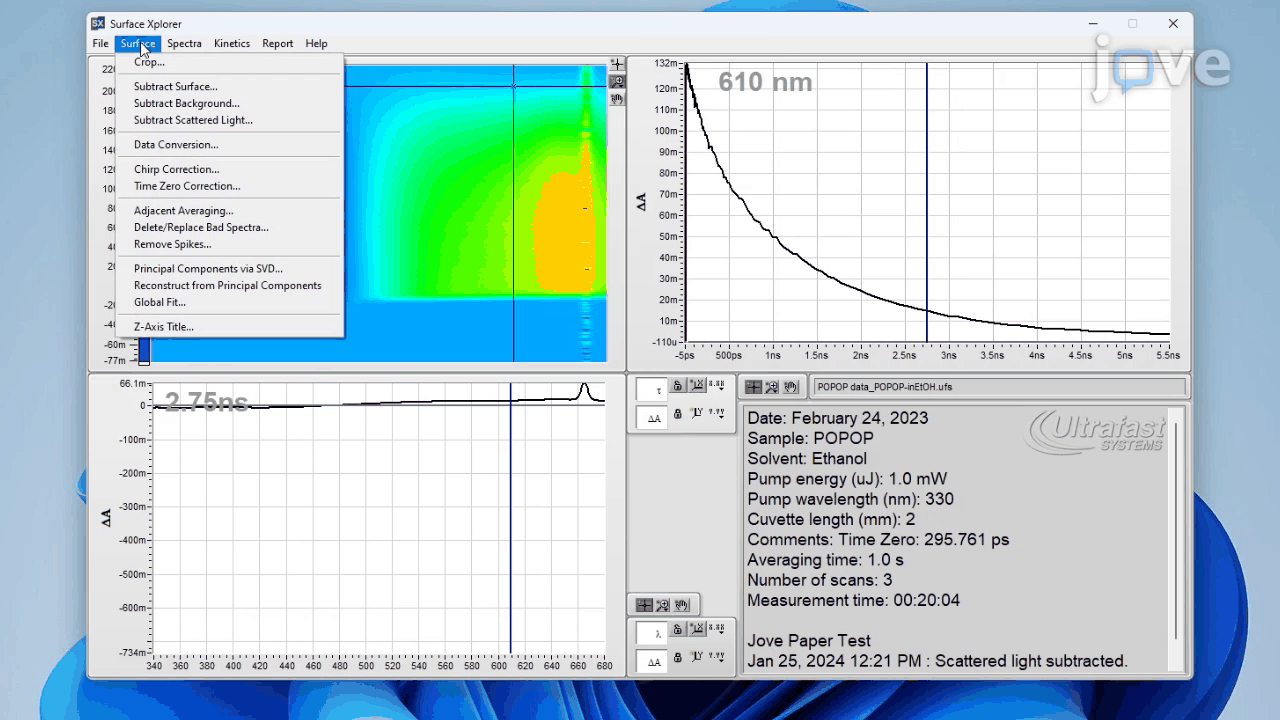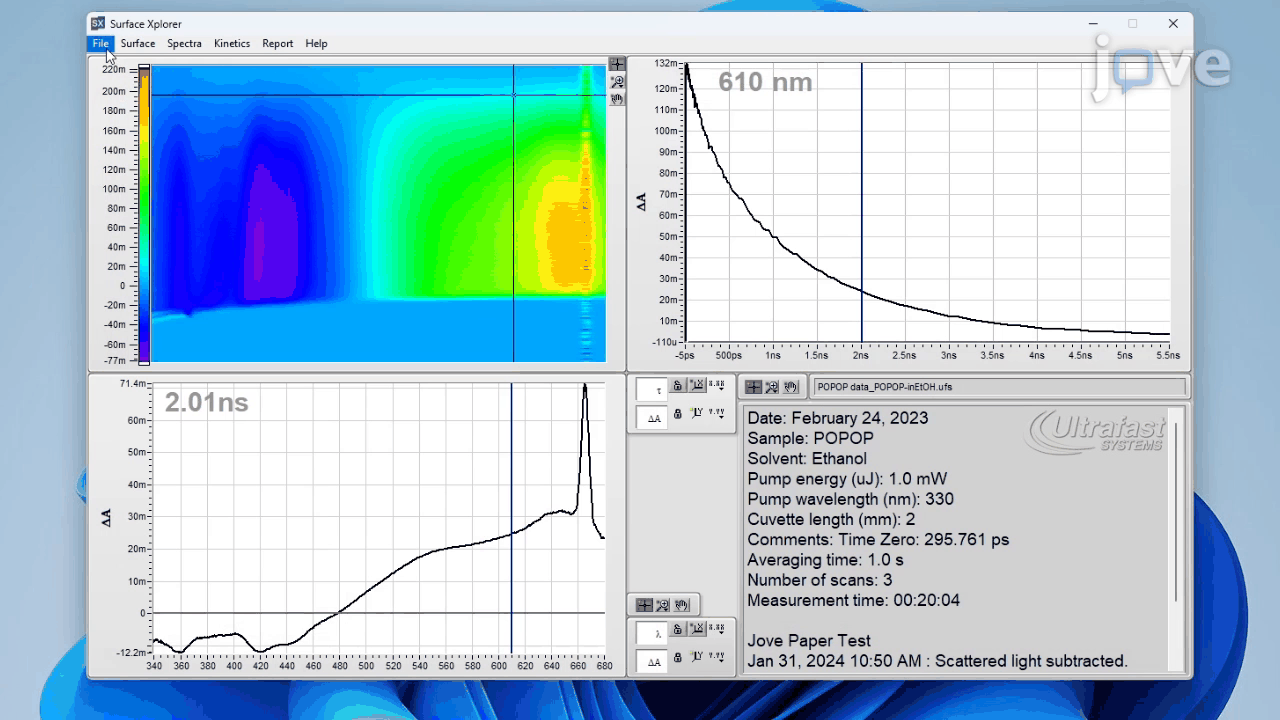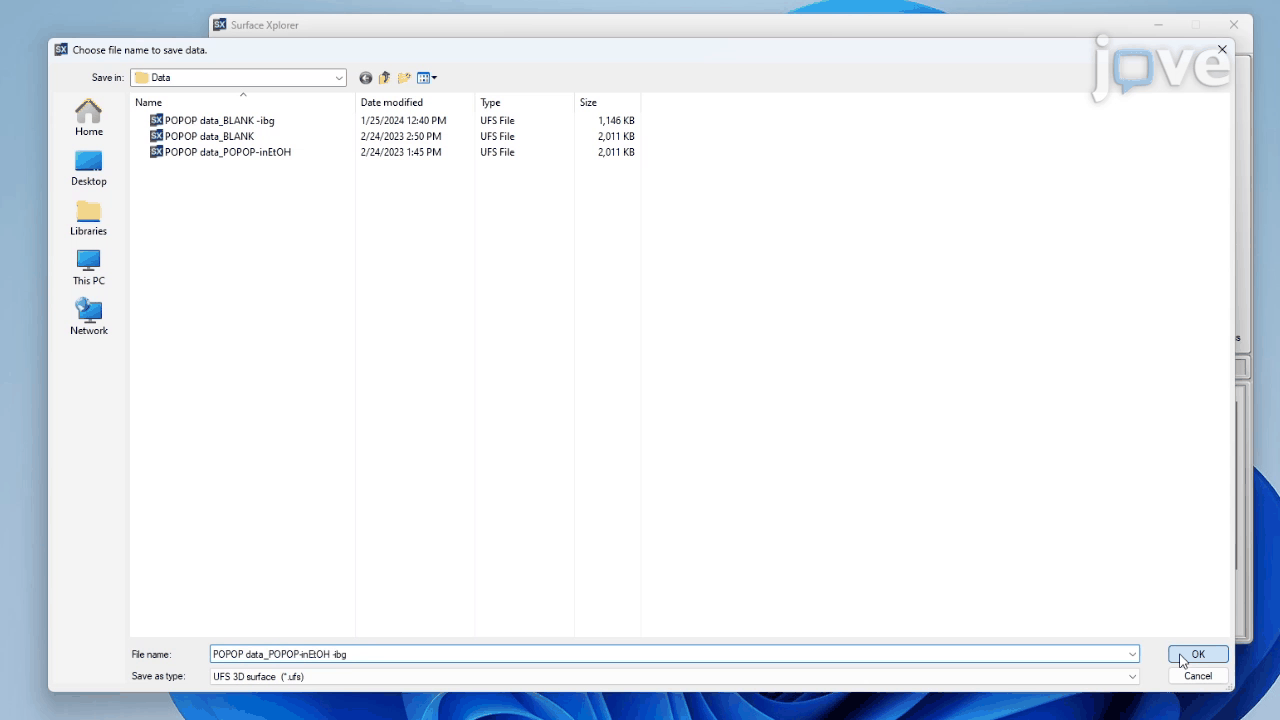
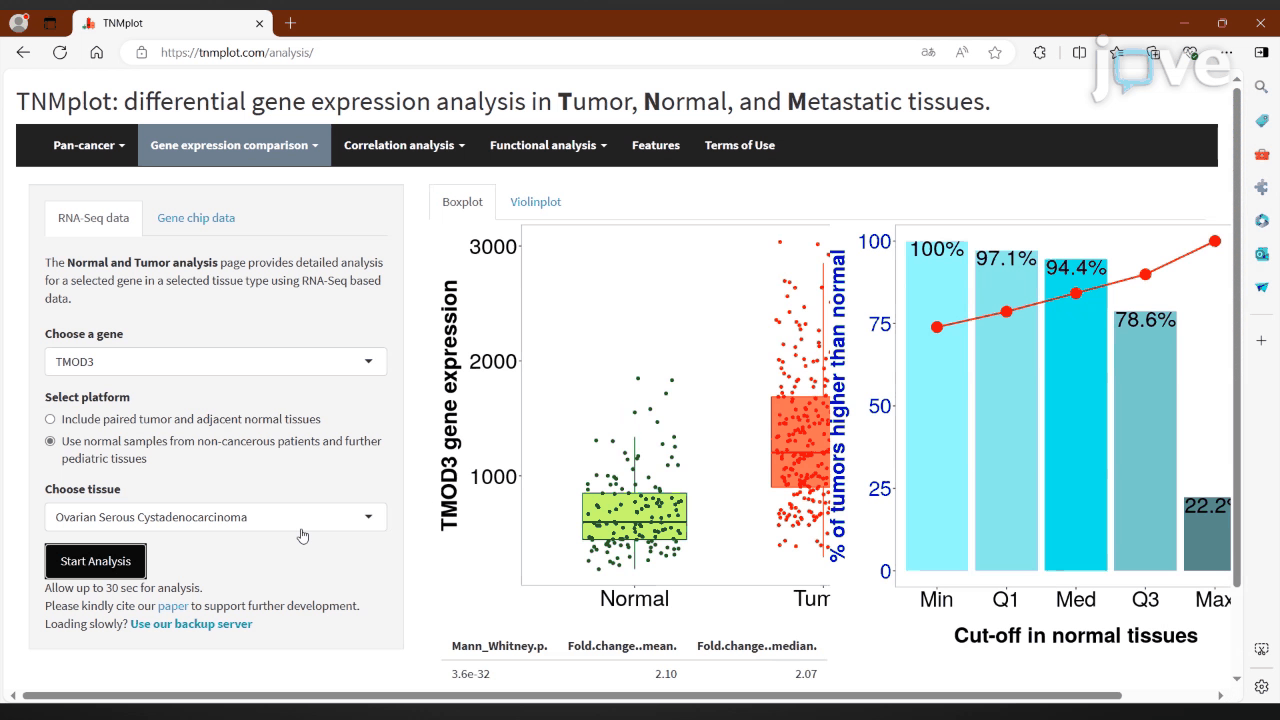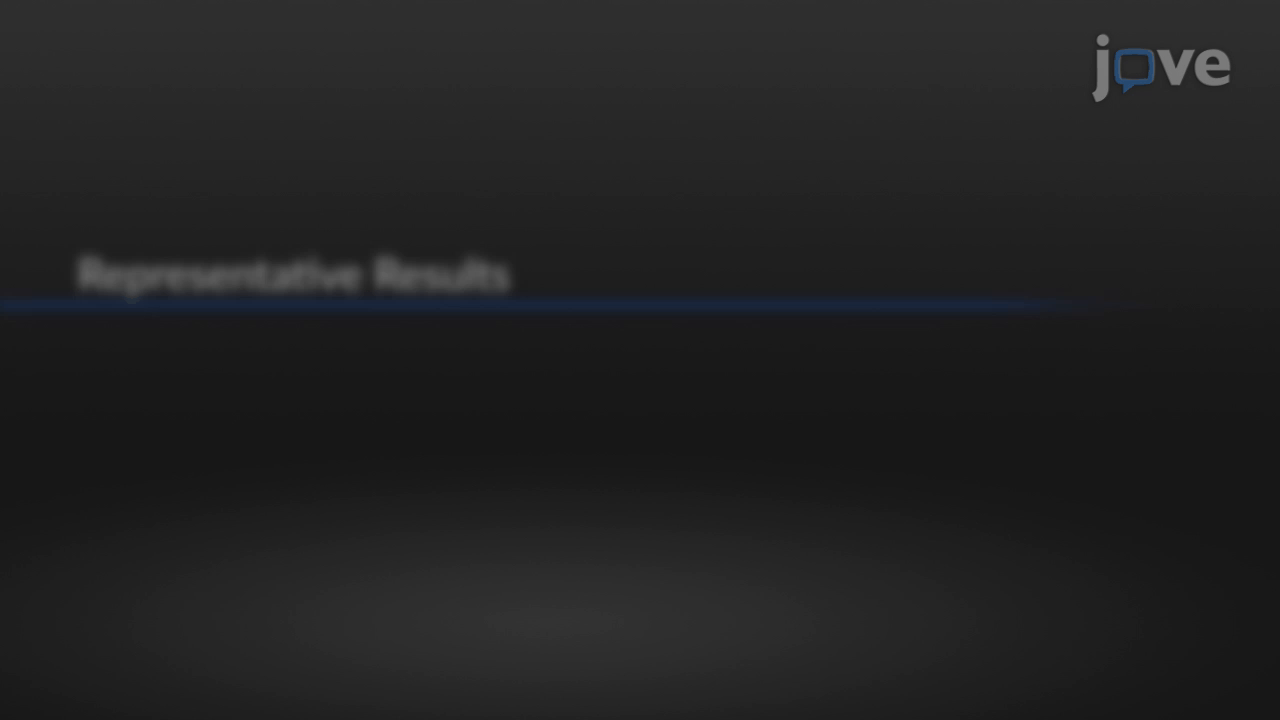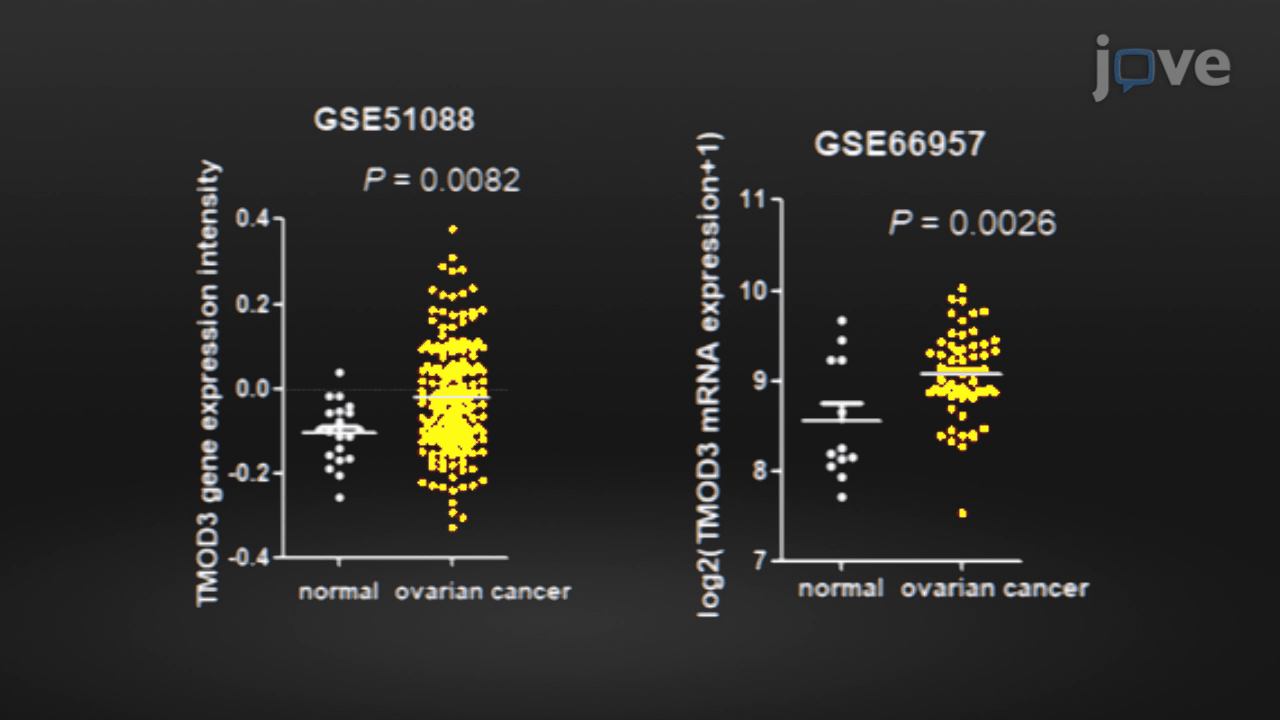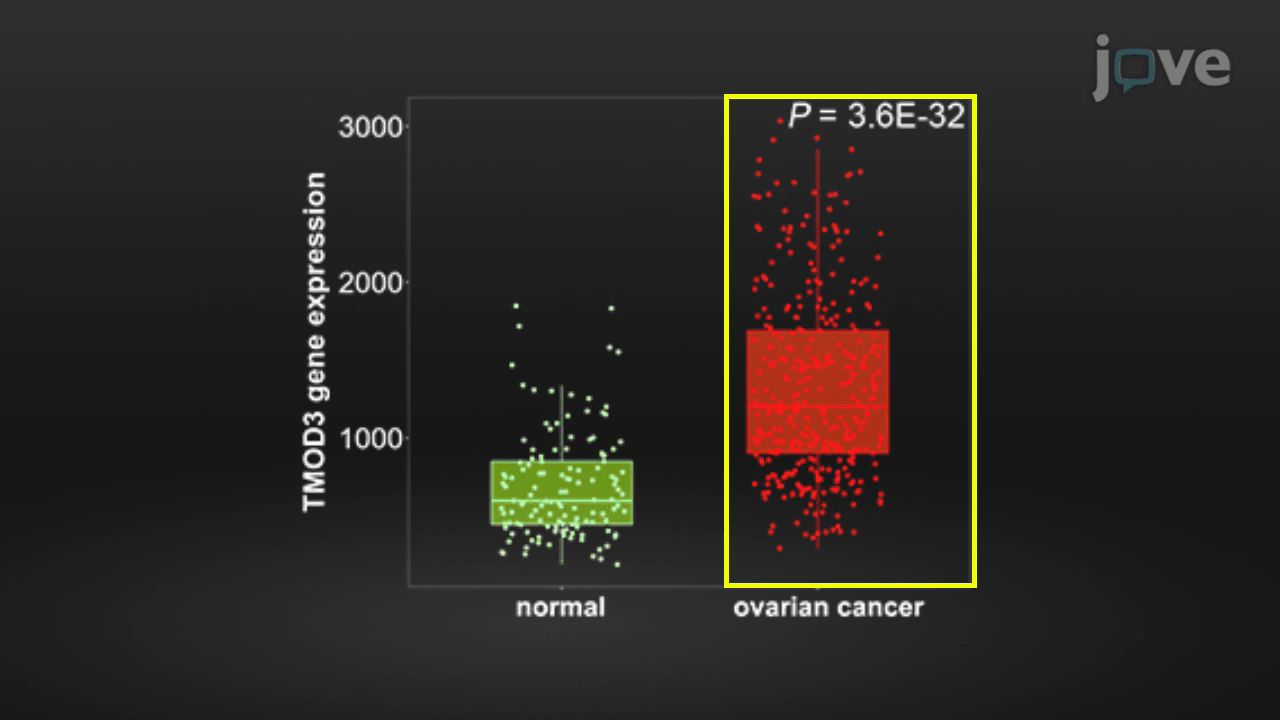
To construct a high-quality benchmark for advanced scientific reasoning, we collect 241 research-grade experimental videos from the Journal of Visualized Experiments (JoVE)↗, a peer-reviewed platform publishing methodological videos across diverse scientific disciplines. These professionally produced and narratively structured videos clearly demonstrate laboratory protocols, scientific phenomena, and technical instrumentation, making them an ideal foundation for a benchmark grounded in authentic scientific practice.
Each video is accompanied by a peer-reviewed manuscript and synchronized audio narration: the manuscript details experimental protocols and results, while the narration provides temporally aligned explanations of each step as it unfolds. This tri-modal alignment—video, audio, and text—supports principled question generation and rigorous answer verification, ensuring that questions are both visually grounded and scientifically meaningful.
We focus on four foundational domains—physics, chemistry, biology, and medicine—covering a wide spectrum of procedural complexity and reasoning challenges. Videos are selected to include measurable variables (e.g., reaction time, temperature, applied force), observable causal relationships, and logical experimental sequences, thereby enabling conceptual, hypothetical, and quantitative reasoning.
This targeted curation ensures that each video in SCIVIDEOBENCH provides rich multimodal cues essential for rigorous scientific reasoning and serves as an ideal testbed for evaluating LMMs.
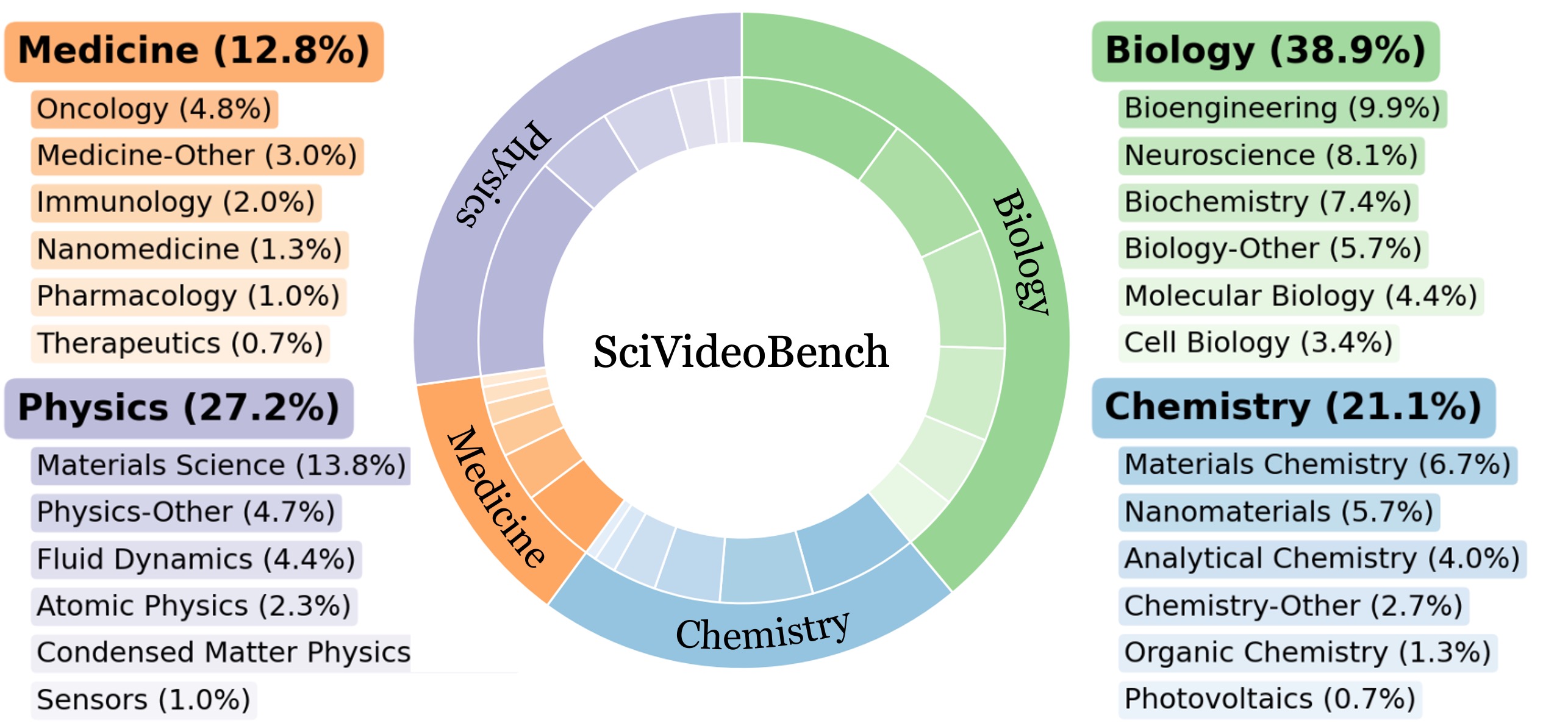
We collected a total of 241 experimental videos spanning four major domains and covering more than 25 distinct scientific subjects, as illustrated in Figure 3. The average video duration is 484 seconds, which ensures that the benchmark reflects the complexity and extended reasoning often required in real-world scientific experiments.
Building upon these videos, we annotated a total of 1,000 challenging questions that demand research-level knowledge for both perception and reasoning. To further capture the nature of academic research and experimental analysis, we carefully designed three distinct question types (conceptual, hypothetical, and quantitative) that reflect common reasoning scenarios observed across the videos.
| Rank | Model | LLM | Size | Overall ↓ | Disciplines | Reasoning Types | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Physics | Chemistry | Biology | Medicine | Conceptual | Hypothetical | Quantitative | |||||
| - | Random Guess | - | - | 10.0% | 10.0% | 10.0% | 10.0% | 10.0% | 10.0% | 10.0% | 10.0% |
| - | Human (Graduate Students) | - | - | 17.4% | 18.1% | 18.7% | 15.9% | 21.2% | 16.1% | 21.2% | 18.9% |
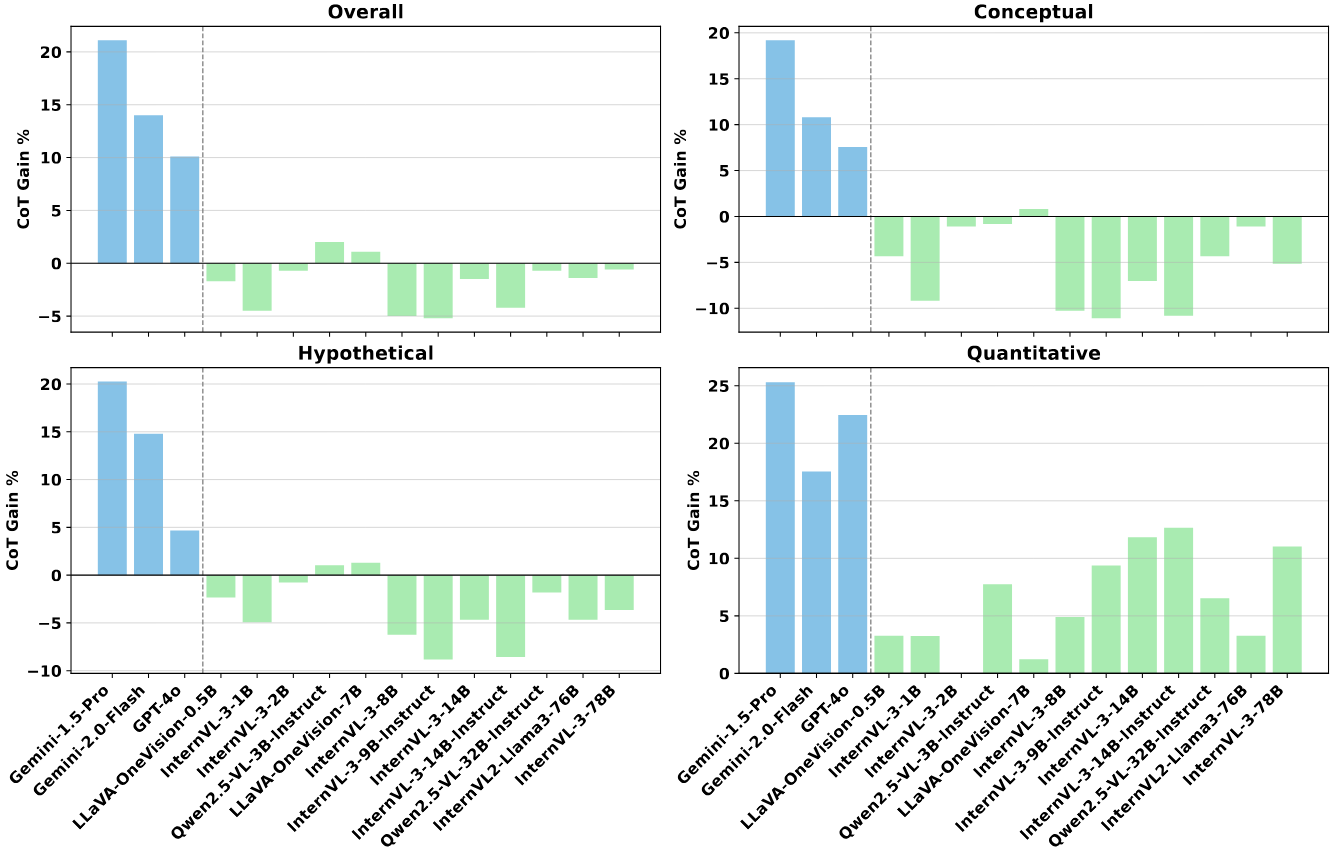
Chain-of-Thought performance gains across proprietary models and open-source models. An obvious difference between proprietary models across all the reasoning aspects can be observed; while for open-source models, quantitative reasoning has a notable performance boost, while the other two reasoning aspects have negative impacts. This phenomenon again demonstrates that the quantitative settings in SciVideoBench require sophisticated multi-step reasoning that can benefit a lot from chain-of-thought prompts.
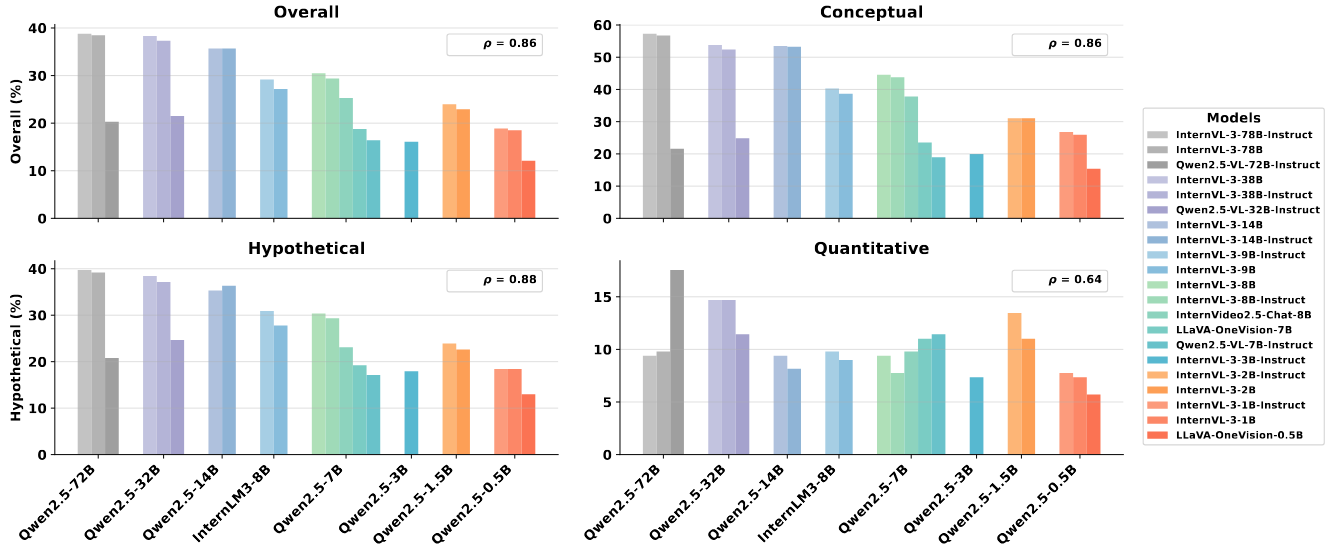
The impact of LLM backbones on the performance. Larger models reliably boost conceptual/hypothetical reasoning, but quantitative gains remain weak and non-monotonic across series.
@article{deng2025scivideobench,
title={SciVideoBench: Benchmarking Scientific Video Reasoning in Large Multimodal Models},
author={Andong Deng and Taojiannan Yang and Shoubin Yu and Lincoln Spencer and Mohit Bansal and Chen Chen and Serena Yeung-Levy and Xiaohan Wang},
journal={arXiv preprint arXiv:2510.08559},
year={2025}
}
